Les PDF « accessibles » et OpenType : un mariage impossible ?
On peut souhaiter utiliser un PDF pour autre chose que sa destination première — un format multi-plateforme de présentation — et le rendre « accessible » : c’est-à-dire lui faire contenir un texte qu’un logiciel peut lire, que ce soit pour l’indexer, y faire une recherche, utiliser des signets, créer automatiquement des liens, le faire lire par un synthétiseur vocal, l’exporter ou le « copier-coller ».
Shlomo Perets de MicroType a écrit des articles très complets sur le sujet (particulièrement dans la série « PDF Best Pratices » : Acrobat’s Find & Search), mais n’a pas couvert en détail l’utilisation d’InDesign et des fonctions OpenType. Le présent article se propose de faire le point sur la question.
Caractères et glyphes
InDesign, aidé de fontes OpenType, est parfaitement dans la logique Unicode : il différencie caractères et glyphes. C’est-à-dire qu’il fait la distinction entre A, la lettre capitale latine A, et Α, la lettre capitale grecque Alpha (deux caractères d’un même dessin — d’un même glyphe —, mais pas du tout d’un même emploi), mais va traiter comme un même caractère avec trois glyphes différents A, A italique ornée, A petite capitale. Donc, si on fait une recherche dans InDesign sur le mot Dvořák, il le trouvera, qu’il soit écrit en bas de casse ou en petites capitales.
Dans une fonte de caractères, chaque glyphe est censé recevoir un nom (je n’entrerai pas ici dans des arguties sur les différences entre TrueType et Type 1), qui peut comprendre jusqu’à 31 caractères, lesquels ne peuvent être que des lettres non accentuées, des chiffres, le point « . » et le tiret bas « _ ». Il y a d’anciennes conventions pour les noms des glyphes, qui font par exemple qu’un « a petite capitale » est appelé Asmall.
Dans une fonte TrueType ou OpenType bien construite, les glyphes sont mis en correspondance avec un code Unicode. Normalement, il ne devrait pas y avoir de codes pour les variantes de glyphes. Mais, puisqu’Unicode prétend supplanter tous les anciens codages de caractères, il intègre comme caractères ce qui devrait rester des glyphes, comme les ligatures fi, fl, ff, ffi et ffl (provenant de vieux codages propriétaires).
Mais tout le monde ne s’en contente pas : par exemple les fontes d’Adobe associent un code Unicode à chaque glyphe. Comme aucun code n’est prévu pour les variantes stylistiques de caractères, tels que les petites capitales, les lettres supérieures, les styles alternatifs de chiffres, Adobe recourt à la ZUP (zone à usage privé : pour le propos de cet article, il suffira de dire que les caractères dans la ZUP sont situés entre U+E000 et U+F8FF). « Asmall » est donc associé à U+F761 (alors que U+0061 est le code de « a »).
Le PDF et le texte
Deux possibilités se présentent : le PDF a été exporté d’une application ou a été distillé à partir d’un fichier PostScript.
Un PDF distillé ne stocke que le nom des glyphes. C’est là que se situe le nœud du problème : Reader (c’est-à-dire Acrobat, Acrobat Reader ou tout système d’indexation compatible, mais de préférence, la version 6 ou 7 d’Adobe Reader ou d’Acrobat) doit reconstruire les valeurs Unicode à partir de ces noms (dans le cas rare où la fonte OpenType utilisée serait présente sur le système, Reader ne sait pas reconstruire ces valeurs à partir des fonctions OpenType). En ce qui concerne les langues à alphabet latin d’Europe occidentale, il connait tous les noms traditionnels des glyphes des codages StandardEncoding, MacRomanEncoding, WinANSIEncoding (les lettres, les chiffres et les symboles courants) et MacExpertEncoding (malgré le nom, rien à voir avec Mac : ce sont les glyphes des fontes Expert — petites capitales occidentales, un style de chiffres alternatifs, les chiffres et lettres supérieurs et inférieurs). C’est insuffisant pour couvrir les possibilités des fontes OpenType (voir plus loin « La solution des fontes »), mais cela explique pourquoi un PDF créé avec des fontes Type 1 Expert peut être accessible s’il est distillé (avec l’application d’une astuce pour les ligatures — voir plus loin).
Un fichier PDF exporté par une application a la possibilité d’inclure une table ToUnicode. Cette table indique la correspondance entre les noms de glyphes présents dans le PDF et des caractères Unicode. Peu importe alors d’avoir des noms de glyphes mal construits ne permettant pas de retrouver le caractère Unicode correspondant : la table fournit l’indication nécessaire.
Si InDesign 2 crée bien une table ToUnicode lorsqu’il exporte un PDF, celle-ci ne permet pas de rendre accessible le texte : les glyphes alternatifs, issus d’une fonte Type 1 Expert ou OpenType, sont associés à des valeurs de la ZUP ! Et, si Reader est capable de faire correspondre le nom de glyphe « Asmall » à « a », il est incapable de faire correspondre U+F761 à U+0061.
En créant cette table ToUnicode, InDesign CS se comporte nettement mieux, mais avec de fortes variations dans la qualité : il reste fortement dépendant de la fonte et des noms de glyphes utilisés — voir ci-après — plutôt que des valeurs Unicode des caractères. Heureusement, InDesign CS 2 a considérablement diminué cette dépendance et peut maintenant exporter des PDF complètement accessibles ou presque.
Il existe une possibilité supplémentaire pour rendre le texte d’un PDF accessible : donner un texte de substitution invisible (mais qui sera lu par Reader) à un bloc texte (fonction ActualText). C’est loin d’être idéal : InDesign ne semble pas capable de le faire, et on doit donc retoucher le fichier dans Acrobat. Nous n’en parlerons pas plus ici.
La solution des fontes
Jusqu’à récemment, Adobe maintenait une liste, appelée Adobe Glyph List, qui prenait acte des pratiques les plus courantes dans les noms attribués aux glyphes (les pratiques d’Adobe et d’Apple, principalement). Mais les choses ont changé : Adobe recommande maintenant les noms de type « uniXXXX » où XXXX est la valeur Unicode en hexadécimal du caractère (exemple : on peut donner à « A » le nom « uni0041 »). Les noms de glyphes en uniXXXX sont interprétés à partir de la version 4 de Reader. Mais ça ne résout pas le problème qui nous occupe, et, de plus, la plupart des anciens noms marchent très bien. Plus important, sont maintenant recommandés certains caractères (caractères compris par Reader également à partir de la version 4) dans les noms de glyphes alternatifs (typiquement les glyphes introduits par des fonctions OpenType) :
- Premièrement, le point pour introduire un suffixe indiquant une variante, de type « t.alt ». Reader ignorera ce point et tout ce qui suit (« .alt » dans l’exemple cité) pour savoir à quel caractère rattacher le glyphe (« t »).
- Et deuxièmement, le tiret bas « _ ».
Quand Reader le trouve dans un nom de glyphe, il décompose le glyphe en caractères. Par exemple, s’il trouve T_h.swash (une ligature Th ornée), il va ignorer « .swash », et décomposer le glyphe en deux caractères : T et h, tous deux parfaitement indexables. Le résultat ne serait pas du tout le même s’il trouvait comme nom de glyphe « Thligswash », qu’il ne serait pas capable de faire correspondre à un caractère.
Pour les petites capitales, il est suggéré le suffixe « .sc » (peu importe d’ailleurs, du moment qu’il y a bien le point séparateur) : Dvořák en petites capitales doit donc être la suite de noms de glyphes « D v.sc o.sc rcaron.sc aacute.sc k.sc » (ou « uni0044 uni0076.sc uni006F.sc uni0159.sc uni00E1.sc uni006B.sc », ce que Reader comprendra tout aussi bien).
Oui, mais…
Ce serait la solution pour les PDF distillés, mais deux problèmes se présentent :
- Primo, InDesign (versions 2, CS et CS 2) insère une espace invisible (espace sans chasse) après une ligature insérée automatiquement (il faut donc désactiver la fonction Ligatures et les ajouter à la main !).
- Secundo, reste à mettre en œuvre ces nouvelles recommandations. Bien qu’Adobe ne se soit engagé à rien, maintenant que toute leur typothèque est convertie au format OpenType, on peut supposer qu’Adobe va travailler à normaliser les noms de glyphes de leurs fontes… C’est le cas des nouvelles versions de Minion Pro et de Myriad Pro fournies avec Adobe Reader 7, et les dernières fontes Adobe converties au format OpenType étaient déjà conformes aux nouvelles recommandations (quoique les anciennes ne soient pas forcément mauvaises — voir ci-contre les deux captures d’écran prises sous FontLab avec deux fontes du CD-ROM d’installation d’InDesign 2). En ce qui concerne les fonderies concurrentes, aucune n’a fait d’annonce à ce sujet.
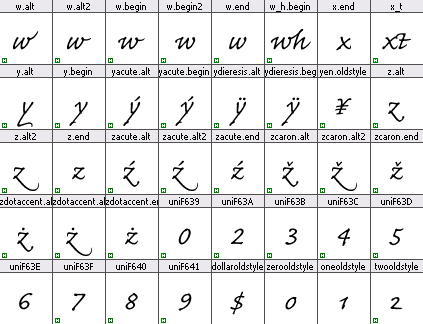
Voici quelques glyphes de la fonte Caflisch Script Pro : la plupart des noms de glyphes sont bien formés, seule une partie des chiffres alternatifs pose problème (les noms de type uniXXXX sont trompeurs, car ils renvoient en fait à des valeurs ZUP — entre U+E000 et U+F8FF —, que Reader ne saura pas faire correspondre à de vrais caractères !).
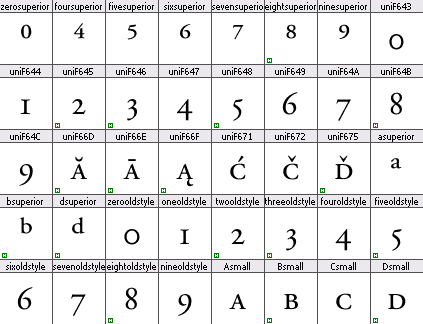
Quelques glyphes d’Adobe Garamond Pro : certains suivent l’ancienne pratique, comme msuperior, Asmall, sixoldstyle. Mais ce sont des noms traditionnels que Reader sait faire correspondre à leurs caractères Unicode respectifs. C’est le monde à l’envers, car, là aussi, les noms de type uniXXXX ont l’apparence d’être bien construits, mais renvoient à des valeurs ZUP !
La fin du problème ?
Même InDesign CS 2 continue à insérer une espace sans chasse après les ligatures en imprimant un fichier PostScript (avec lequel l’accessibilité repose entièrement sur les noms de glyphes) : rendre accessible un PDF distillé suppose donc toujours plusieurs précautions. Par contre, cette nouvelle version d’InDesign génère une table ToUnicode très correcte : un PDF exporté avec cette version a de fortes chances d’être parfaitement accessible.
Références
Adobe Glyph List Specification
PDF Reference, version 1.6 (Section 10.8, Accessibility Support, et Appendice D, Characters Sets and Encodings)
Use of the Unicode Private Use Areas by Software Vendors
Note : remerciements chaleureux à Franck Petit d’Adobe France pour son aide à la préparation de cet article.